
How We Improved Our Testing Pipeline
.png)
Building software of any kind is a complex and time-consuming process. It involves designing, ensuring code quality, managing product roadmaps, continuous feedback, and most importantly testing.
At Leen, we take testing seriously. It isn't just a checkbox, it's a critical part of our development process. We manage highly sensitive security data, and therefore ensuring every piece of code functions as intended is highly critical. Testing enables Leen to confidently push code and catch potential issues early.
However, as our test suite and codebase expanded, we were noticing that our testing pipeline was slowing down our development speed and becoming a bottleneck. Here's how we tackled it:
The Problem
Our testing setup was simple and sometimes simplicity can be inefficient.
We had over 300 functional and integration tests, many of which were making external API and database requests.
Our process included spinning up postgres database container using Docker before executing pytest, and we relied on a global db_engine and a db_session fixture to reset the database (by dropping and recreating all tables) before each test.
This ensured test isolation but resulted in significant overhead –– running this on GitHub Actions took around 14 minutes!
The default pytest setup with asyncio used only a single CPU core, even though more cores were available.
While the GitHub Action runner had 2 CPUs, our local machines, equipped with 12-core M3 Pro MacBooks, were significantly underutilized, resulting in longer dev cycles.
How We Overcame The Problem
We used pytest-xdist, a plugin that enables you to execute tests in parallel across multiple machines or CPUs, essentially allowing you to spawn a number of worker processes and distributes the tests across them. Now since there was still only one database and these multiple workers expect to interact with isolated databases, it throws up another challenge: race conditions.
A race condition arises when multiple processes or threads are simultaneously trying to modify and retrieve shared data, resulting in unforeseen and unintentional outcomes (source: Noname security)
To address these race conditions, we turned to Testcontainers (an open-source framework for provisioning throwaway, on-demand containers for development and testing use cases).
By using Testcontainers, we could spin up a separate Postgres database for each worker, allowing for the isolated environments for our tests.
With the modifications, conftest now looked something like this:
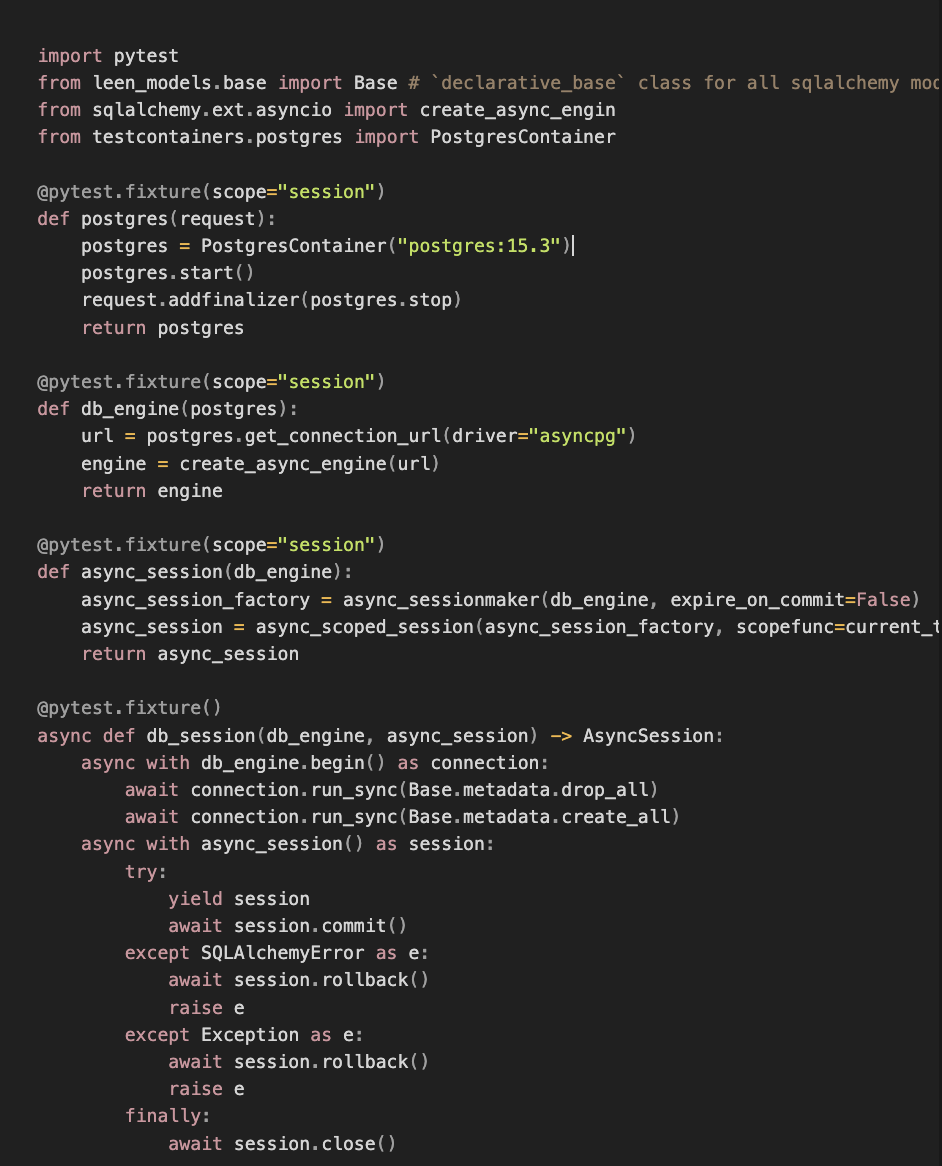
By setting the postgres, db_engine, and async_session fixtures at the session scope, we ensured that they were initialized once per worker. The db_session fixture is scoped at the function level, meaning that all the test function will receive database session with cleaned up database.
The Result
These simple changes combined with 4 parallel worker on 2 core runner in our GH pipepline, we reduced our testing time from ~14 minutes to ~5.5 minutes!
Enhancing Efficiency: What We Can Do To Improve This Further
We've identified further ways to improve the efficiency and potentially reduce our testing time further.
Deleting and recreating the table takes around 200 milliseconds for each tests. It can improved by:
- Creating 2 database instances per worker and rotating between them after each test execution and reset the rotated database in background
- Creating a template database instance in postgres fixture with all tables. Instead of dropping and recreating tables, regenerate the database from this template. This is extremely fast (no concurrency issues or other overhead slowing you down) because Postgres copies the structure at the file level.
CREATE DATABASE mydb **TEMPLATE my_template**;Caveats
- All tests must be isolated from each other. The tests may behave unexpectedly if 2 tests share the same resources such files in local FS or S3 bucket.
- If 2 tests share the same resource, you can add @pytest.mark.xdist_group("<group name>") marker to those test function. Pytest will group the tests so that only one test accesses the shared resource at a time.
Alternatively
We can add new database for each test in the single postgres database. It may have similar or slightly better performance compared to Testcontainer, but it would come at the cost of a poor developer experience since everyone would need to ensure that their local test databases are set up correctly.

.png)
.png)

.png)